长字段的索引
示例
SELECT
*
FROM
employees
WHERE
first_name = 'Duangkaew'如果索引对应的字段内容长度一般,可以直接使用索引即可,如果内容的长度特别长,那么创建索引占用的空间也就会比较大,而且查询的要率也比较低
方法
创建额外的字段,如first_name_hash,存储时,使用mysql内置的CRC32("123...")方法存储
INSERT INTO employees
( emp_no,
birth_date,
first_name,
last_name,
gender,
hire_date,
first_name_hash )
VALUES
(111111,
'2022-12-07',
'beo........',
'12',
'M',
'2022-11-07',
CRC32( 'beo........' ))只需在first_name_hash上添加索引即可,查询修改为
SELECT
*
FROM
employees
WHERE
first_name_hash = CRC32('Duangkaew')
AND -- 即便存在hash冲突,也能返回正确结果
first_name = 'Duangkaew'first_name_hash应具备以下条件:
- 字段的长度应该比较小,SHA1/MD5 是不合适的
- 应当尽量避免hash冲突,目前比较流行的是CRC32()和FNV64()
示例
SELECT
*
FROM
employees
WHERE
first_name = 'Duangka%'对于这种索引,是无法通过添加额外列进行处理,但是mysql支持前缀索引
alter table employees add key (first_name(5))索引值越大,性能越差,可以根据索引选择性公式进行设置
索引选择性 = 不重复的索引值/数据表的总记录数对应的sql示例
select count(distinct LEFT(first_name,5))/count(*) from employees如果业务场景是通过后缀进行查询,但是mysql是没有后缀索引的,所以可以通过建立一个新的字段,例:first_name_reverse ,存储的时候,将字段反转过来进行存储,然后对该字段添加前缀索引,即可实现后缀索引
局限性
无法做order by,group by ;无法使用覆盖索引
单列索引 VS 组合索引
- SQL 存在多个条件,多个单列索引,会使用索引合并
- 如果出现索引合并,往往说明索引不够合理
- 如果SQL暂时没有性能问题,暂时可以不做处理
- 组合索引要注意索引列顺序,要符合【最左前缀原则】
示例
SELECT
*
FROM
salaries
WHERE
from_date = '1986-05-06'
AND to_date = '1987-05-06'在未创建索引的时候,运行sql耗时:
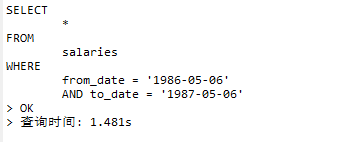
接着,为这两个字段分别创建单列索引后再次运行
ALTER TABLE employees.salaries
ADD INDEX f(from_date),
ADD INDEX t(to_date);
使用explain查看运行情况

type提示触发了索引合并,使用的key为f和t,extra中提示为f和t做了求交集的操作
接着删除所有的索引,然后为这两个字段创建组合索引,再次运行
ALTER TABLE employees.salaries
DROP INDEX f,
DROP INDEX t,
ADD INDEX f_t(from_date, to_date);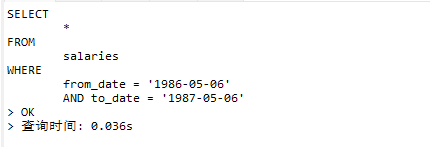
运行explain

type变成了ref,性能比两个单列索引性能触发的index_merge要好一些,因为两个索引的求交集行数并不多,多以示例的差异性并不明显,如果求交集的行数增多,那么求交集的开销也会增加,那么性能差异就会更加明显
覆盖索引
对于索引x,select的字段只需要从索引中就能获得,而无需到表数据里获取,这样的索引就叫覆盖索引。
对于查询字段非主键索引时,如果不覆盖索引,需要先通过非主键获取到主键,然后再通过主键到表中找到对应的数据,如果覆盖索引,则可以直接返回索引,省略掉两步
- 尽量只返回想要的字段,避免写 select * ,这样如果索引的条件能满足就回使用覆盖索引,同时减少网络的开销
SELECT
from_date ,
to_date
FROM
salaries
WHERE
from_date = '1986-05-06'
AND to_date = '1987-05-06'运行EXPLAIN

使用覆盖索引,并不会修改执行过程,但是一旦使用了覆盖索引,会在extra中提示useing index
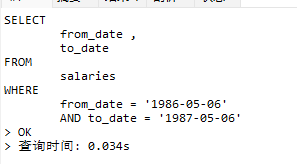
相应的查询时间,也有所减少
重复索引、冗余索引、未使用的索引
索引也不是万能的,在增删改的时候,索引的维护也是有开销的。索引越多,开销愈大,所以在条件允许的情况下,要创建尽可能少的索引。
重复索引
在相同的列上按照相同的顺序创建的索引
应该尽量避免重复索引,如果发生重复索引,应该删除
冗余索引
如果已经存在了索引Index(A,B),又创建了索引Index(A),那么索引Index(A)就是索引Index(A,B)的冗余索引
冗余索引也要尽量避免,但是要注意,避免掉进坑里
示例
为salaries表创建索引Index(from_date, to_date),然后用Explain执行语句
EXPLAIN SELECT
*
FROM
salaries
WHERE
from_date = '1986-06-26'
ORDER BY
emp_no;结果

type为ref,extra为Using where; Using filesort,无法为order by是用索引,使用了文件排序
为salaries表创建索引Index(from_date),然后用Explain执行语句

type为ref,extra为Using where;
因为对于非主键索引,会在叶子节点上存储主键值,所以会先查找存储的主键值,然后再去查找对应的数据,所以对于Index(from_date)来说,某种意义上,等同于Index(from_date,emp_no),所以对于order by 字句也可以使用索引,而对于Index(from_date, to_date)来说等同于Index(from_date, to_date,emp_no),但是我们的查询语句中并没有to_date,所以order by 字句无法使用索引。
所以如果项目中出现了这种的冗余索引,是不可删除的。
未使用的索引
某个索引根本就没有使用过。
需要避免,直接删除