分页语句
limit , - offset: 返回结果第一行的偏移量(想要跳过多少行)
- size: 指定返回多少条
示例
查询employees中第一页的数据,每页的数据量为10条数据
SELECT * FROM employees LIMIT 0,10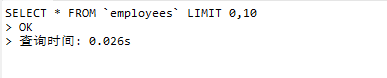
想要查询其它页,只需要将offset设置为对应size的倍数即可,但是LIMIT有个问题,就是在offset非常大的时候,查询会非常慢
示例
查询employees中第30001页的数据,每页的数据量为10条数据
SELECT * FROM employees LIMIT 300000,10
如果查询的offset设置的更大,那么这个时间就会更长。
EXPLAIN 排查
EXPLAIN SELECT * FROM employees LIMIT 300000,10
可以看到,查询的type为All,扫描的行数是298981,这里设置的offset越大,rows就会越大,针对offset非常大的情况,就需要做一些优化
方案1:覆盖索引
覆盖所以可以大幅度减少查询的时间,修改sql为
SELECT emp_no FROM employees LIMIT 300000,10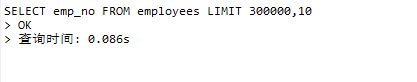
EXPLAIN 排查
EXPLAIN SELECT emp_no FROM employees LIMIT 300000,10
type变为了index,发生了全索引扫描,全索引扫描相比全表扫描还是要快的
如果我们确实需要返回全部的字段,可以使用覆盖索引+join或覆盖索引+子查询的方式
方案2:覆盖索引+join
示例
SELECT
*
FROM
employees a
INNER JOIN ( SELECT emp_no FROM employees LIMIT 300000, 10 ) b ON a.emp_no = b.emp_no
# 因为On的字段都是emp_no,所以也可以简写成using(emp_no),结果是一样的
SELECT
*
FROM
employees a
INNER JOIN ( SELECT emp_no FROM employees LIMIT 300000, 10 ) b USING(emp_no)

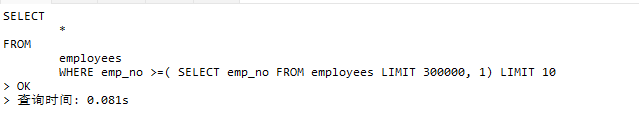
方案3:覆盖索引+子查询
示例
SELECT
*
FROM
employees
WHERE emp_no >=( SELECT emp_no FROM employees LIMIT 300000, 1) LIMIT 10
方案4:范围查询+limit语句
如果我们能拿到查询条件上一页的主键的最大值,那么sql就会很简单
示例
从一开始的sql中,我们可以查到,第一页最大id为10010,那么查询第二页的sql就变成了
SELECT
*
FROM
employees
WHERE
emp_no > 10010
LIMIT 10如果要查询第三页,只需要将emp_no修改即可,依此类推,这种方案的好处是,不管查询多少页,每次扫描的行数都是10,但是使用的前提是,需要拿到上一页的主键最大值,否则这种方案就没法实施。
方案5:起始主键+结束主键
如果我们能拿到查询条件的起始主键值和结束主键值,那么sql就可以变成
SELECT
*
FROM
employees
WHERE
emp_no BETWEEN 20000 and 20010这种情况下,limit语句都不需要,直接变成了范围查询
方案6:禁止传入过大的页码
示例
在百度搜索任意字符
然后点击下一页,查看浏览器的地址
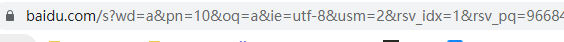
然后点击第三页,查看浏览器的地址
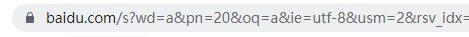
可以发现,地址中多了pn,可以判断出,pn就是页码,于是,我们将pn改为990,即查询第100页的数据
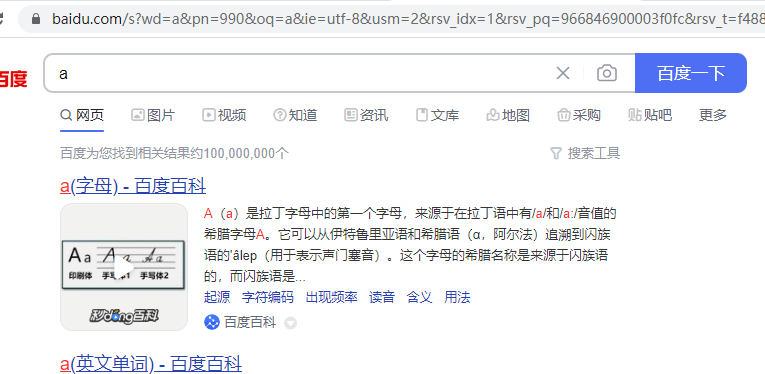
回到了第一页,然后我们输入750
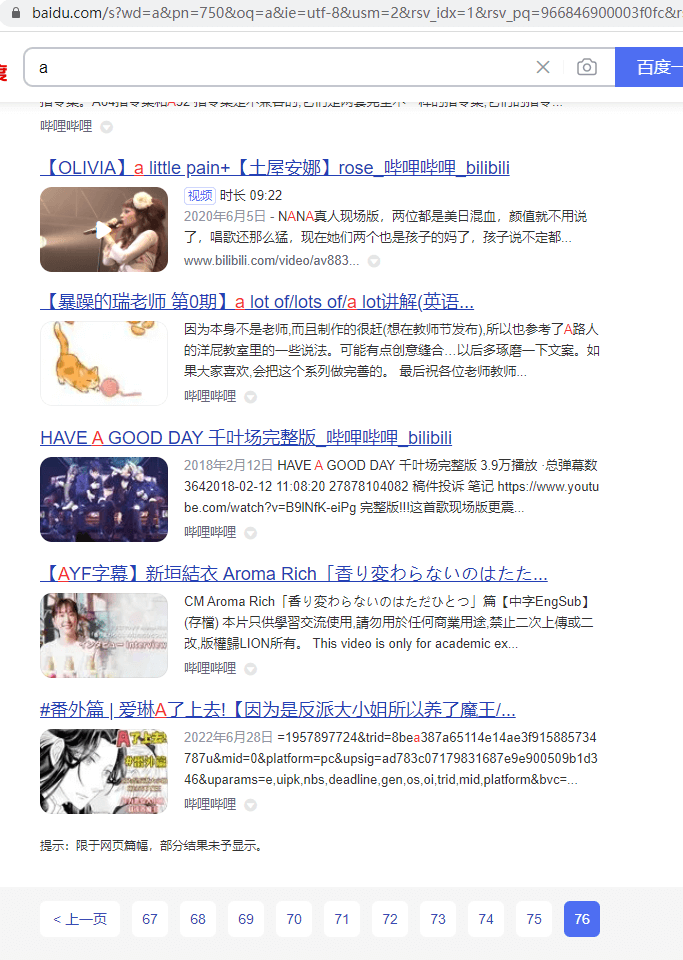
成功了,而且可以看到百度最大支持到76页。对于一般来说,很少有人会搜索到700多条还没有找到自己想要的数据,76的结果是完全够用的。