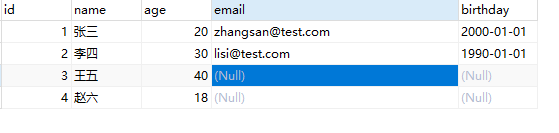
首先准备一张测试表
CREATE TABLE user_test_count (
id int(11) NOT NULL,
name varchar(50) DEFAULT NULL,
age int(11) DEFAULT NULL,
email varchar(60) DEFAULT NULL,
birthday date DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;表中如下数据
运行count(*)
EXPLAIN SELECT COUNT(*) FROM user_test_count
使用了主键索引,接着在表中字段创建一个索引
ADD INDEX usc_email(email);再次运行

使用了新创建的索引,索引长度是183
再次新增索引
ADD INDEX usc_birthday(birthday);运行

使用了usc_birthday,索引长度是4
结论
- 当没有非主键索引时,会使用主键索引
- 当存在非主键索引时,会优先使用非主键索引
- 如果存在多个非主键索引时,会使用最小的非主键索引
原因
表的存储引擎为innodb,innodb非主键索引的叶子节点存储的是索引+主键。主键索引叶子节点存储的是主键+表数据。mysql是以页为单位的,在一个页里面,非主键索引可以存储更多的条目,对于一张表,如果有一百万条数据,使用非主键索引扫描的page可能有100个,使用主键索引,可能就会有500个,于是使用非主键索引比主键索引要好
运行sql
EXPLAIN SELECT COUNT(email) FROM user_test_count结果

使用了索引
直接运行
SELECT COUNT(email) FROM user_test_count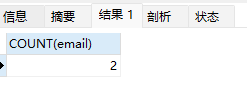
直接运行
SELECT COUNT(*) FROM user_test_count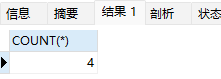
结论
count(字段)只会针对该字段进行统计,使用这个字段上的索引(如果存在索引的话)
count(字段)会排除掉该字段值为null的行,count(*)则不会
除count(*)和count(字段以外),还有count(1),直接运行
EXPLAIN SELECT COUNT(1) FROM user_test_count
也是使用了最小的索引字段,在官方文档中这样写道

对于innodb来说,count(*)和count(1)没有区别,性能上是一样的,没有性能差异
SQL_CALC_FOUND_ROWS
在实际项目中,分页查询数据时,会有这样的两条sql,分别查询数据和总数
SELECT * FROM salaries LIMIT 0,10;
SELECT count(*) FROM salaries;而使用SQL_CALC_FOUND_ROWS以后,mysql就会在查询完毕数据后立刻查询count(*)的数据,然后再数据后增加
SELECT FOUND_ROWS() as total_count;即可获取这个count
mybatis中可以这样使用
对于的dao层
public List listSalaries();对于的service层
List result = testExtDao.listSalaries();
List extResults = (List) result.get(0);
Integer count = ((List) result.get(1)).get(0); 缺点
官方文档中提到,这种方式在8.0.17以后,已经被废弃,后续可能会被删除